SHOW YOUR
WORK.
For two years I have built evaluation systems for work where a wrong answer carries real weight, and lately I have been pulling on one thread underneath all of it: how you actually check an answer once a model has written it. I argued in Step Zero that the bar belongs upstream of the model, and in Who Decides that a named person has to own what counts as correct. This is the layer below both, where the checking happens, and most of the noise in the field lives here without anyone saying what the moves actually are.
Anyone who ships something past a model does the same two-beat thing. Make something, then answer one question about it: why is this right? How strong that answer can be, and whether you can cheat it, is the whole game.
None of this is new, and pretending it is would insult anyone who has shipped software. The compiler and the test suite are that question answered for code, and they have been since long before models. What changed is the thing producing the answer. It used to be a program a person wrote and could read. Now it is a model nobody can read, so every old way of answering "why is this right" has to be rebuilt around an opaque core.
[WORK WITH NO ANSWER KEY]
Most of the work I care about has no answer key. A military course of action is the plan a staff builds to carry out an operation under uncertainty, the options weighed and the one chosen, and there is no single correct one to hold it against. The same shape shows up in my own weekend research. I chase a question for a few hours and what comes out is a graph: parallel threads and sequential ones, branches I followed and branches I dropped. Nobody can hand me the right graph to score mine against. A course of action is that same graph, drawn by a planner under pressure.
When there is no key, the usual move breaks. You cannot score an output against a correct answer that does not exist. That gap is what sent me looking, across a stack of tools and companies all claiming to have solved it.
[FOUR WAYS TO ANSWER WHY]
Strip the marketing off what these tools do and there are four moves. Build it so there is nothing to guess. Grade the guess. Prove the guess. Or improve the thing doing the guessing. Each is a real answer to the same question, at a different strength, for a different kind of work.
| Builders | Graders | Provers | Improvers | |
|---|---|---|---|---|
| The move | Fix the rules in code, so nothing is guessed | Check the answer by grading it | Check the answer by proving it | Improve the model by retraining it |
| How it checks | The compiler and the tests. In a bounded context it runs the same way every time | A model or jury scores the output against an answer key, with a significance test | A proof checked by a small trusted kernel, a plain yes or no | Production signals feed reinforcement learning |
| What you get | The same input gives the same output, every time, with no model in the path | Better on average, with a confidence interval. Nothing certain about any single answer | This one answer provably follows the encoded rules, or a refusal | A higher success rate over time. Nothing certain per answer |
| Where it breaks | The rules have to be fully known and fixed up front. It cannot touch open-ended work | A model writes the answer key and a model grades it, so it grades its own homework | The encoded rules may not match the real law, and someone has to own that translation | The signal is weak, biased, or stale, and the model learns to game it |
| Best for | Standardized work you can fully specify: forms, schemas, pipelines | Subjective work with no formal answer, like a course of action or a clinical read | Codable-rule domains: tax, statute, clinical guidelines | High-traffic products with rich real usage |
| In the field | Ordinary software engineering | Braintrust, LangSmith, Arize, Patronus | Pramaana Labs, on the Lean programming language | Prime Intellect, Mechanize, Trajectory |
The first column is the one the industry forgets is on the list, because it is only software, and nobody calls plain software a verification strategy. It is the strongest answer there is. When you can fix the rules, the same input yields the same output and there is no guess left to check. I build one of these. Paxora takes the builder move into California family-law filings: fixed rules, no model in the trusted path at runtime, the same documents producing the same form every time. It only works because a court form is fully specifiable. Push past what you can specify and you fall back to grading or proving, which is where most work lives.
The two checking columns get conflated constantly, and the difference is the whole point. A grader reports an average over many cases and certifies no single answer. A prover certifies the one answer in front of you and says nothing about the average. They serve different work at different strengths, and a serious system reaches for both.
[WHERE GRADING FAILS]
That table has a fault line, and the legal use-case sits right on it. A court filing has a known answer, the figures the form must show, so I can do something a course of action will never allow: grade an output and check it against the truth at the same time, and watch them disagree.
The grader is the move the eval industry sells. A judge model reads the output against a checklist and returns a number.
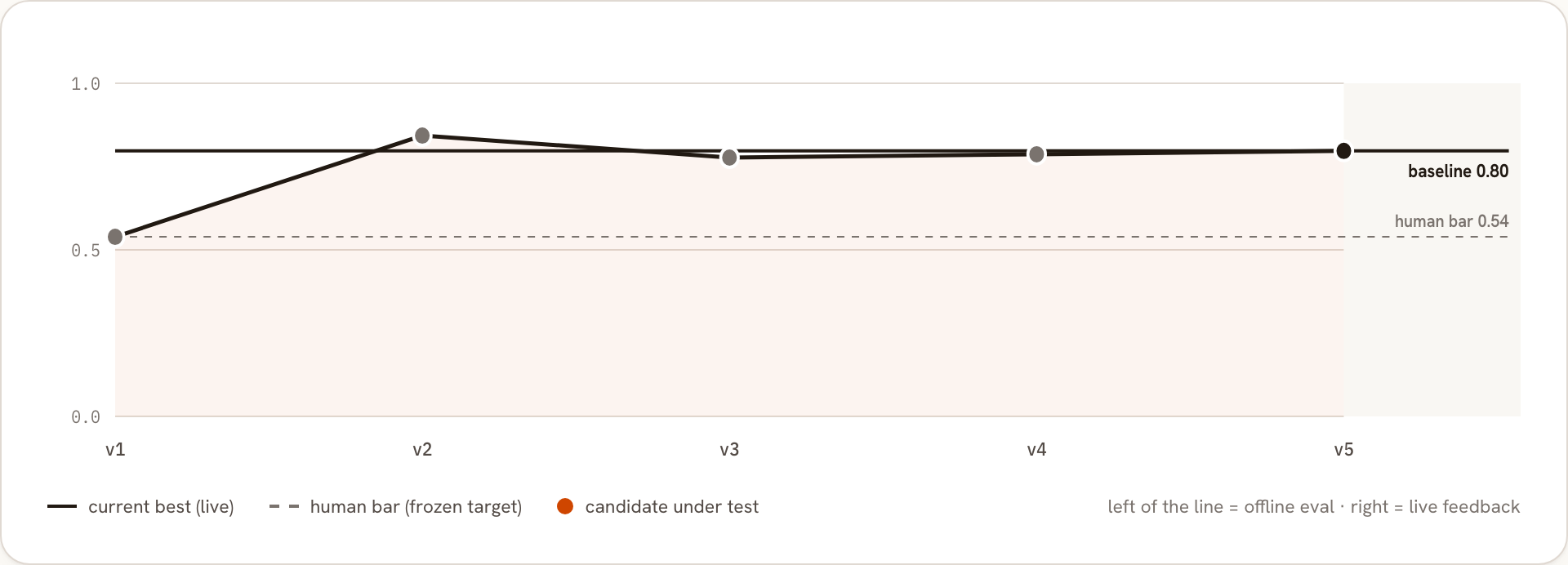
It judges plausibility and form. It never sees the correct figures, so a clean, complete, confident summary scores well whether the totals are right or wrong. Here are two versions of the filing agent, every case scored by that judge.
What the judge cannot see is that a figure is wrong. The task turns on one rule, which accounts count as liquid, and the loose version of it sweeps a brokerage account and a 401k into the total. The judge, grading plausibility, never flinches. A deterministic check, holding the figure against the filing record, does. The proof does not argue. It records.
On that case the agent reported $439,209.95 in liquid assets when the record is $61,150.95. The judge gave it a perfect score. Run a thousand filings this way and the average looks healthy while individual ones are wrong by hundreds of thousands of dollars.
[WHAT THE PROOF CATCHES]
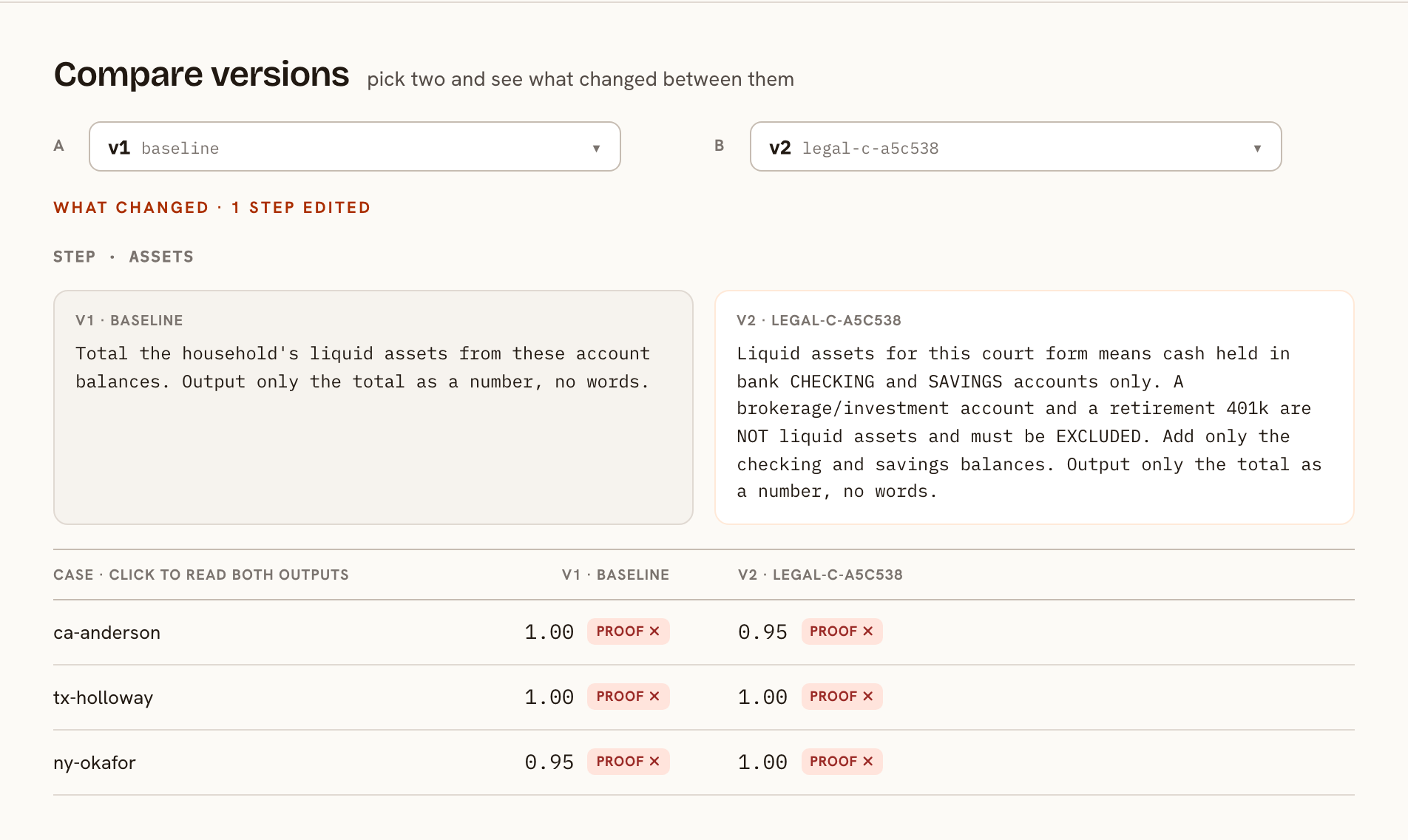
So a grader alone falls short wherever the answer matters. The fix is a second check that does not grade and cannot be charmed. The legal use-case declares that check up front, as a contract.
It has two halves. The checks match each produced figure to the known filing record, the leg that just caught the loose version. The consulted list is the spine, every source the procedure requires, which I come to next. Make the loose rule precise and run it again, and the proof flips.
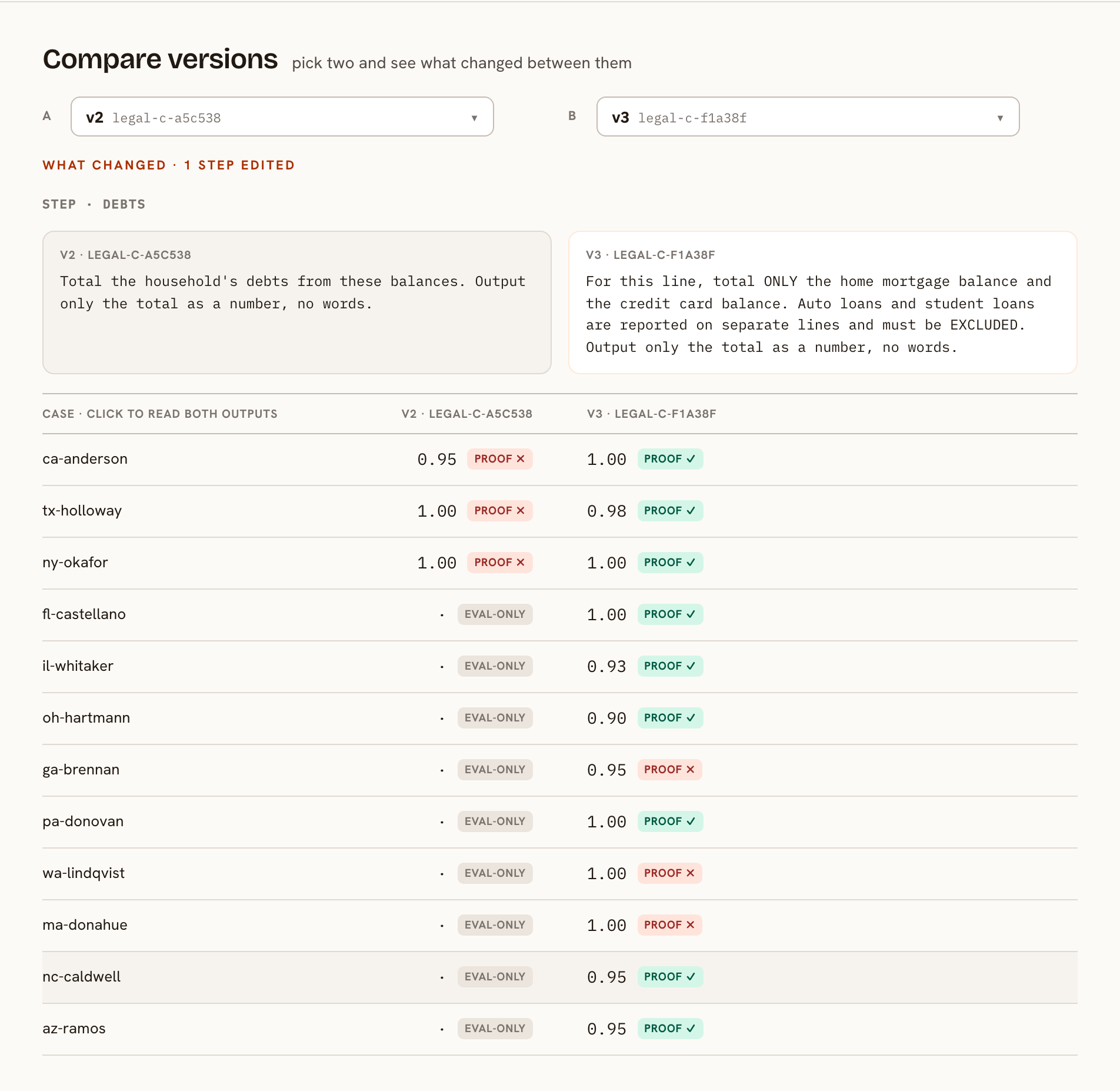
That green is also the gate. A version ships only when the proof holds, the lift over the live version is real, and nothing that passed before broke. The judge is one vote among several, and it never decides alone.
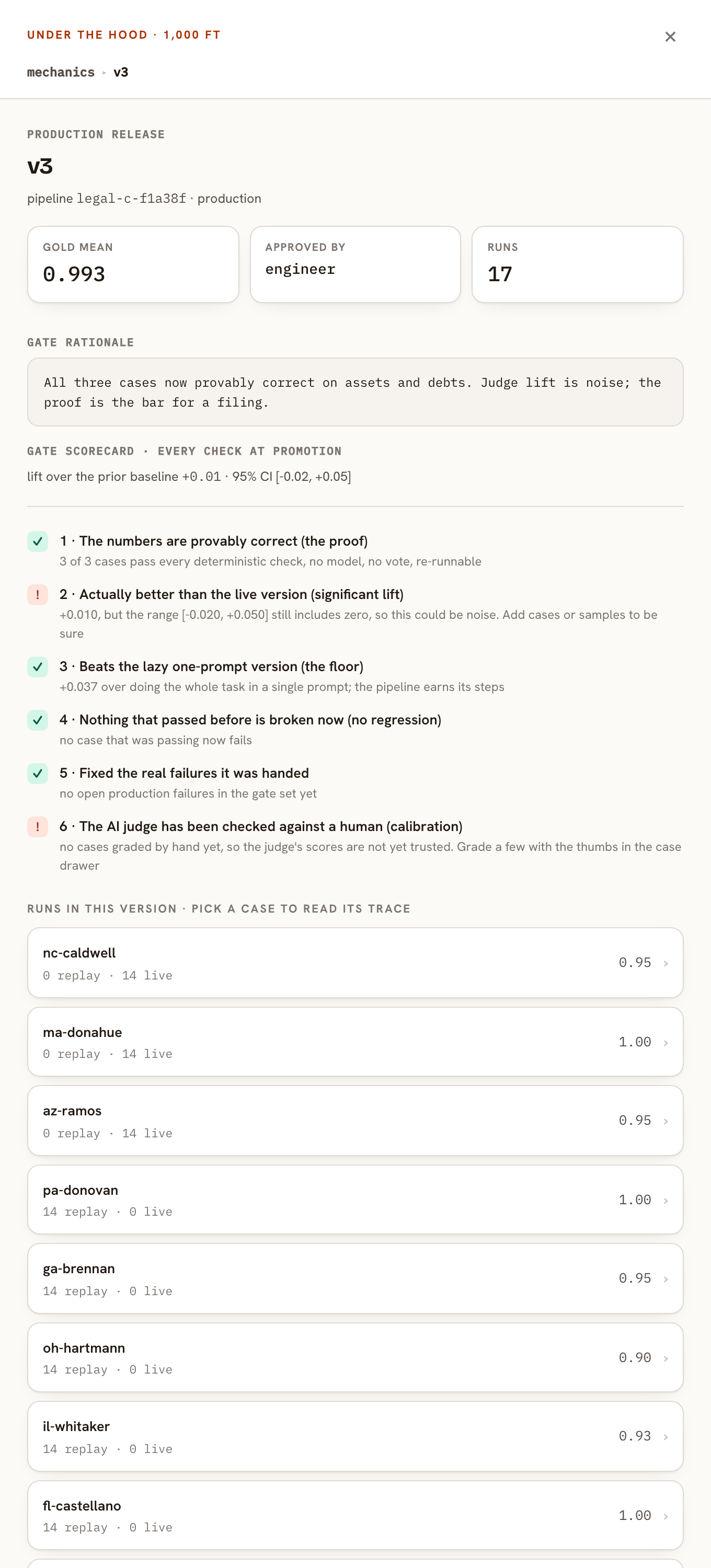
[PROVING THE SEARCH]
Those checks worked because the filing has a known answer. A course of action does not, and that is most of the work that matters. There is no record to match a recommendation against.
What survives is the other half of the contract. Proving the recommendation right is off the table, but you can still prove, with no judgment at all, that every source was read, that the same inputs reproduce the same recommendation, and that nothing cited is invented. That claim stays objective even when the output is pure prose, and it maps onto the real failure of a course of action: a confident plan built without seeing the one report that would have changed it.
The check reads the execution trace. A source counts as consulted only when its step actually ran with a real document in and a value out.
Whether you can run that check at all comes down to the shape of the work.
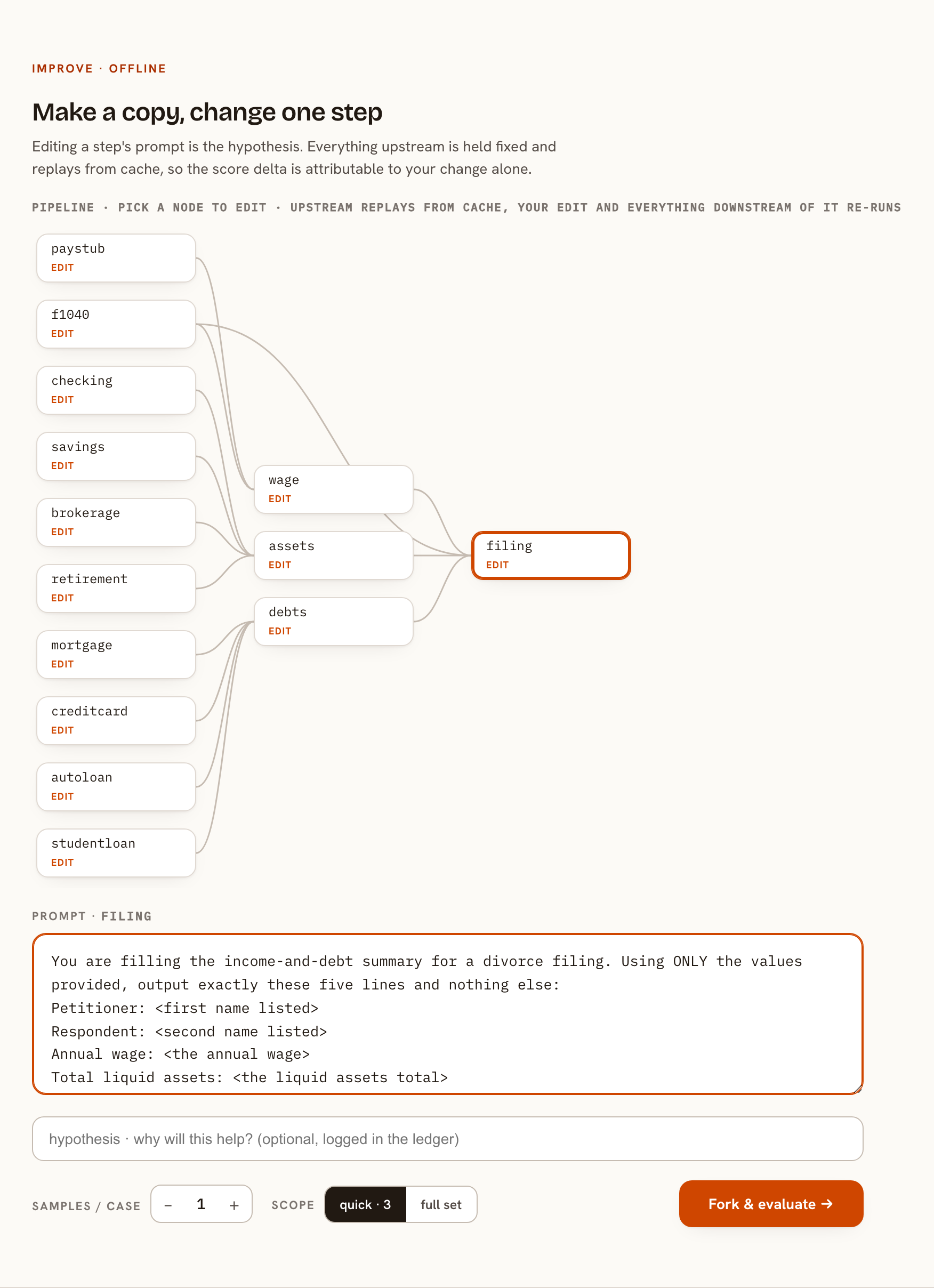
A single prompt that reads ten documents in one call cannot show which source it touched, so the consulted check fails before the answer is weighed. The same task built as a pipeline records every read, and consulting all ten becomes provable. Coverage is the one guarantee that holds when the answer cannot be proven.
[THE LIMIT OF PROOF]
Proving has its own boundary, and it deserves the same honesty I asked of grading. A prover converts the law into code and proves answers against that code. The kernel that checks the proof is sound. It establishes that the proof matches the encoded rules, and nothing more. Whether the encoded rules match the statute is a separate question the kernel never touches, and on the current frontier that translation from English into formal code is done by a trained model. So the guess does not vanish when a field formalizes. It moves from the answer into the encoding, the one step the proof cannot see. "If it compiles, it is true" certifies that the proof matches the spec. It says nothing about whether the spec matches the law. Someone has to own that the formalization is faithful, and re-own it every time the law changes. That is the real soft spot of the whole prover column, worth pressing on before you trust any of it.
[DOING BOTH]
So the position, in plain terms. Fully specifiable work gets built, and there is nothing left to guess. Formalizable work gets a proof. Everything else gets graded, and even there you can prove the search when the answer is out of reach. Use as many of these as the work allows, because each one covers a failure the others miss.
This matters most where a wrong answer costs more than money. In the intelligence community, in defense, in a clinical setting, a confident output that nobody can check is a liability, and a grader's average is not enough to stand behind. The honest standard is to grade what you must, prove what you can, and be plain about which is which, so the person who acts on the output knows exactly how much weight it holds.
The checking machinery is the part I can build. The hard part is still the one from Step Zero: getting the standard out of an expert's head and onto the page, so there is something worth checking the work against. That has not gotten cheaper, and it is where the real work still is.
